
We take a break from the H-1B analysis and set the stage here for future posts that require us to work in environments with distributed compute & storage. A simple way to simulate them is with Virtualbox as the provider of VMs (‘Virtual Machines’) & Vagrant as a the front-end scripting engine to configure, start/stop those VMs. The goal for this post is to build a clustered virtual appliance offering elasticsearch as a service that can be consumed/controlled by a host machine. The artifacts used in this article can be downloaded from Github.
1. Background
Backend capacity scaling in the face of increasing front-end demand has generally been addressed by replacing weaker servers with more powerful ones, cpu/ram/disk wise – so called ‘Vertical Scaling’. This is as opposed to ‘Horizontal Scaling’ where more servers are simply added to the mix to handle the extra demand. Intuitively, the later model is appealing as it sounds like less work! In the traditional RDBMS centric applications, there was no choice, and vertical scaling actually made sense because it is difficult to do joins across large distributed data tables. But vertical scaling has its limits but more importantly becomes very expensive well before hitting those limits. NoSQL databases that skimp on relations (the ‘R’ of RDBMS) to allow for simpler horizontal scaling have become the go–to datastores now-a-days for applications that need to scale large as in facebook/google large. The reader is referred to Hadoop the Definitive Guide, where Tom White goes over these scale issues in depth. Applications running on distributed storage & cpu have to deal with their own issues like keeping a cpu busy on the data that is ‘local’ to it, making sure that cluster members are aware of one another and know who has what piece of the data, and perhaps elect a leader/master as needed for coordination, writes etc… as the implementation details vary across systems. We are not going to delve into all that here but our goals for this post are more pragmatic:
-
- Develop a means to run a virtual cluster of a few nodes (‘guests’) where the guests for now are carved out of my laptop by Virtualbox. Later we will extend the same means to run services on a cluster of nodes provided by AWS
- Install a distributed datastore on this cluster of guests. Elasticsearch right now, so we can go through the mechanics
- Confirm that this ‘virtual Elasticsearch appliance’ offers a completely controllable service from the host.
2. VirtualBox
We use Oracle’s Virtualbox as the provider of guest virtual hosts. Virtualbox is free to use, runs very well on my linux laptop (Ubuntu 15.04 64bit on my laptop with 8 core i7, 2.2GHz CPU, 16GB ram), and has extensive documentation on how to control the various aspects of the hosts to be created. There are prebuilt images as well of any number of open source linux distributions that you can simply drop in for the guest OS. It offers a variety of networking options (sometimes daunting as I found out) to expand/limit the accessibility/capability of the guests. For our purposes we prefer a ‘host-only’, ‘private’ network with the following criteria.
- The guests and hosts should be able to talk to each other. We want the guests to form a cluster and work together to enable a service. The host should be able to control & consume the services offered by the cluster of guests.
- The guests should be able to access the internet. This is so they can download any OS updates, software packages they need in order to run whatever application elasticsearch, mongo etc…
- The guests cannot be accessed from outside. This is just a made up requirement at this time as I do not want to expose the service to the outside. The host is the consumer of the service and it may roll that into its own service that it can offer to the outside if it so desires.
- Lastly, for ease of use & portability each guest should have an IP address & name ‘assigned’ at the time of its creation.
Installing Virtualbox and creating VMs of various kinds is quite straightforward. Based on a prebuilt image that I downloaded, I could set up a single VM fine the way I wanted. Used NAT for adapter1, host-only for adapter2, and activating the host-only interface on the VM. I wanted to clone it and build other guests, but I had troubles getting the networking right in a reliable/repeatable fashion. Networking was never my strong suite and after playing some with their networking options both via the GUI & command-line, I gave up trying to master it. I am sure the networking gurus out there can do it, so it is certainly not a limitation of Virtualbox but a limitation on my part.
But more reasonably though, I did not want to be logging into the guest to set up stuff or worse – changing settings for each guest via the GUI that VirtualBox offers. That will definitely not scale, a pain to reproduce, and is error-prone. I wanted a turn-key solution of sorts wherein I could script out all aspects of the VM cluster creation upfront, and simply run it to have that cluster created with all the tools installed, started and rearing to go. Vagrant allows one to do that easily as I happily found out. Basically they have already figured out the exact sequence of ‘vboxmanage’ commands ( & their options!) to run to set up a cluster specified by some high level requirements… which was what I was trying to do and they have already done it! Plus as the cluster set up with vagrant is file based, we can version it, and share it (small compared to an OVA file) to have the cluster reproduced exactly elsewhere. May be I am biased because of the issues I had with the networking setup, but the reader is referred to discussions similar to Why Vagrant or Why should I use Vagrant instead of just VirtualBox? The real appeal of Vagrant in the end for me was that it can seamlessly work with other VM providers such as AWS, VMWARE via plugins, so the same config files/scripts can be reused simply by changing the provider name. Carving resources out of my laptop to build VMs is fine here for getting the mechanics down, but it is not going to give performant cluster!
3. Vagrant
Having spent a lot of words trying to get here, we jump right in with no further ado. We prepare a text file by the name ‘Vagrantfile’ with high level details on the cluster we are going to build. Running vagrant init at the command prompt will generate a sample file that can be edited to our liking. Here is how our file looks like to meet our requirements laid out in section 2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# -*- mode: ruby -*- # vi: set ft=ruby : nguests = 2 box = "hashicorp/precise64" memory = 8256/nguests # memory per box in MB cpuCap = 100/nguests ipAddressStart = '192.168.1.5' Vagrant.configure("2") do |config| (1..nguests).each do |i| hostname = 'guest' + i.to_s ipAddress = ipAddressStart + i.to_s config.vm.define hostname do |hostconfig| hostconfig.vm.box = box hostconfig.vm.hostname = hostname hostconfig.vm.network :private_network, ip: ipAddress hostconfig.vm.provider :virtualbox do |vb| vb.customize ["modifyvm", :id, "--cpuexecutioncap", cpuCap, "--memory", memory.to_s] end hostconfig.vm.provision :shell, path: "scripts/bootstrap.sh", args: [nguests, i, memory, ipAddressStart] end end end |
It is a ruby script but one does not need to know a lot of ruby, which I did not. Here is a quick run down on what it does.
- We want to set up a 2 node cluster (Line #3).
- We choose Ubuntu 12.04 LTS 64-bit as the OS image on each. Vagrant downloads it if that image has not already been downloaded before to the local repo (‘The Default Machine Folder’ for VirtualBox) (Line #4)
- My laptop has 16gb RAM and I want to leave 8gb for the host at all times. The rest is divided equally among the guests. Likewise the guests are limited to a fractional use of the cpu. (Lines 5, 6)
- We loop over each guest:
- Setting its image (#13), and name (#14).
- We choose a ‘private_network‘ mode and set the IP address ( # 15). This gives us the network model we wanted in Section 2.
- Line # 19, is about provisioning the VM with tools, and apps. Extremely powerful & handy. We can automate the process of bringing up each member of the cluster with just the apps we want that guest to be responsible for. No need to ssh to each guest and go through separate installs – a great time saver! Besides simple shell scripts Vagrant allows for other mechanisms like docker, chef, ansible, puppet etc… for provsioning process. Here we use a shell script ‘bootstrap.sh’ to which we pass the arguments we need, to set up Elasticsearch.
That is all for Vagrant really. The rest is all good old shell scripting at which we are old hands – fabulous! Once the scripts are ready, we run vagrant up to have the cluster come up, do our work and run vagrant halt to power the cluster down. Until we run vagrant destroy the cluster will retain its apps/config/data so we can run vagrant up anytime to use the cluster and its services.
Provisioning Elasticsearch
This is fairly straightforward. The key thing to know is that Vagrant automatically enables one shared directory between the host & guests. That is the directory where the file ‘Vagrantfile’ is located. On the guests this directory is accessed as ‘/vagrant’. So if we have file ‘a/b/c/some_file’ at the location where ‘Vagrantfile’ is on the host, that ‘some_file’ can be accessed on the guest as ‘/vagrant/a/b/c/some_file’. We use this feature to share pre-downloaded packages we need to install on guests, and any scripts we want to run, post boot time. The ‘bootstrap.sh’ script looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/env bash nguests=$1 guestNumber=$2 memory=$3 ipAddressStart=$4 # Install some utilities that we will need apt-get -y install unzip apt-get -y install curl # Install java mkdir -p /opt/software/java cd /opt/software/java ; tar zxvf /vagrant/tools/jdk-8u65-linux-x64.tar.gz # Install & Start up elasticsearch /vagrant/scripts/elastic.sh $nguests $guestNumber $memory $ipAddressStart |
We install some utilities we will need to start with (Lines #9, #10), install java from the shared location (Lines #13, #14). Finally we run the script to install elasticsearch (Line #17).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
#!/usr/bin/env bash usage="Usage: elastic.sh nguests thisguest memory ipAddressStart. Need the number of guests in the cluster, this guest number, es-heap memory in MB like 2048m, and startingIp like 192.168.0.5 if clustered ... " # Install Elastic, Configure & Start function setUnicastHosts() { local unicast_guests="discovery.zen.ping.unicast.hosts: [" for i in $(seq 1 $nguests); do unicast_guests+='"guest-es'$i unicast_guests+=':9310"' if [ "$i" -ne "$nguests" ]; then unicast_guests+=',' fi done unicast_guests+=']' echo "$unicast_guests" } # Add to /etc/hosts for convenience & restart networking... function setEtcHosts() { guest_list="" for i in $(seq 1 $nguests); do guest_list+=$ipAddressStart$i' guest-es'$i$'\n' done echo "$guest_list" > guests_to_be_added cat /etc/hosts guests_to_be_added > tmp ; mv tmp /etc/hosts /etc/init.d/networking restart } if [ "$#" -eq 4 ]; then nguests=$1 thisguest=$2 memory=$(expr $3 / 2) memory+="m" ES_HEAP_SIZE=$memory ipAddressStart=$4 ES_HOME=/opt/software/elasticsearch/elasticsearch-1.7.2 mkdir -p /opt/software/elasticsearch cd /opt/software/elasticsearch ; unzip /vagrant/tools/elasticsearch-1.7.2.zip cp /vagrant/elastic/start-node.sh $ES_HOME cp /vagrant/elastic/stop-node.sh $ES_HOME cp /vagrant/elastic/elasticsearch.yml $ES_HOME/config guest_name="guest-es"$thisguest node_name=$guest_name"-node1" unicast_guests=$(setUnicastHosts) if [ "$thisguest" -eq 1 ]; then mkdir -p $ES_HOME/plugins/kopf cd $ES_HOME/plugins/kopf ; tar zxvf /vagrant/elastic/kopf.tar.gz fi perl -0777 -pi -e "s|ES_HOME=/opt/elasticsearch|ES_HOME=$ES_HOME|" $ES_HOME/start-node.sh perl -0777 -pi -e "s/ES_HEAP_SIZE=2g/ES_HEAP_SIZE=$memory/" $ES_HOME/start-node.sh perl -0777 -pi -e "s/host_name=localhost/host_name=$guest_name/" $ES_HOME/start-node.sh perl -0777 -pi -e "s/host_name=localhost/host_name=$guest_name/" $ES_HOME/stop-node.sh perl -0777 -pi -e "s/node_name=node0/node_name=$node_name/" $ES_HOME/start-node.sh perl -0777 -pi -e "s/$/\n$unicast_guests/" $ES_HOME/config/elasticsearch.yml else echo $usage exit 1 fi setEtcHosts $ES_HOME/start-node.sh |
An elasticsearch node is a running instance of elasticsearch, and a server can run multiple instances – resources permitting of course. All the nodes that are part of a cluster have the same ‘cluster.name’. Starting with some boiler-plate configuration files that are shared between the host & guests, the script above modifies them based on the arguments passed to each guest during provisioning. The file ‘config/elasticsearch.yml’ for all guest nodes will be augmented with a list of all members of the cluster.
|
1 |
discovery.zen.ping.unicast.hosts: ["guest-es1:9310","guest-es2:9310"] |
The script ‘start-node.sh’ prepared for ‘guest2’ runs the following command to start up the elasticsearch node ‘guest-es2-node1’.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
/opt/software/elasticsearch/elasticsearch-1.7.2/bin/elasticsearch -d -Des.cluster.name=es-dev -Des.node.name=guest-es2-node1 -Des.http.port=9210 -Des.transport.tcp.port=9310 -Des.path.data=/opt/software/elasticsearch/elasticsearch-1.7.2/data -Des.path.logs=/opt/software/elasticsearch/elasticsearch-1.7.2/logs -Des.path.plugins=/opt/software/elasticsearch/elasticsearch-1.7.2/plugins -Des.path.conf=/opt/software/elasticsearch/elasticsearch-1.7.2/config -Des.path.work=/opt/software/elasticsearch/elasticsearch-1.7.2/tmp -Des.network.host=guest-es2 -Des.network.publish_host=guest-es2 -p /opt/software/elasticsearch/elasticsearch-1.7.2/pid |
where ‘es-dev’ is the name of the cluster we are building. The command on ‘guest1’ to start ‘guest-es1-node1’ would be identical to the above, except for replacing ‘es2’ with ‘es1’. Further it appends
|
1 2 |
192.168.1.51 guest-es1 192.168.1.52 guest-es2 |
to ‘/etc/hosts’ file on each guest and restarts the network.
Indexing from the host
We fire up our virtual elastic cluster simply by running vagrant up . Because we have installed the ‘kopf’ plugin on ‘guest1’ during provisioning, we can verify that the cluster is up, accessible from the host & ready to be put to work.
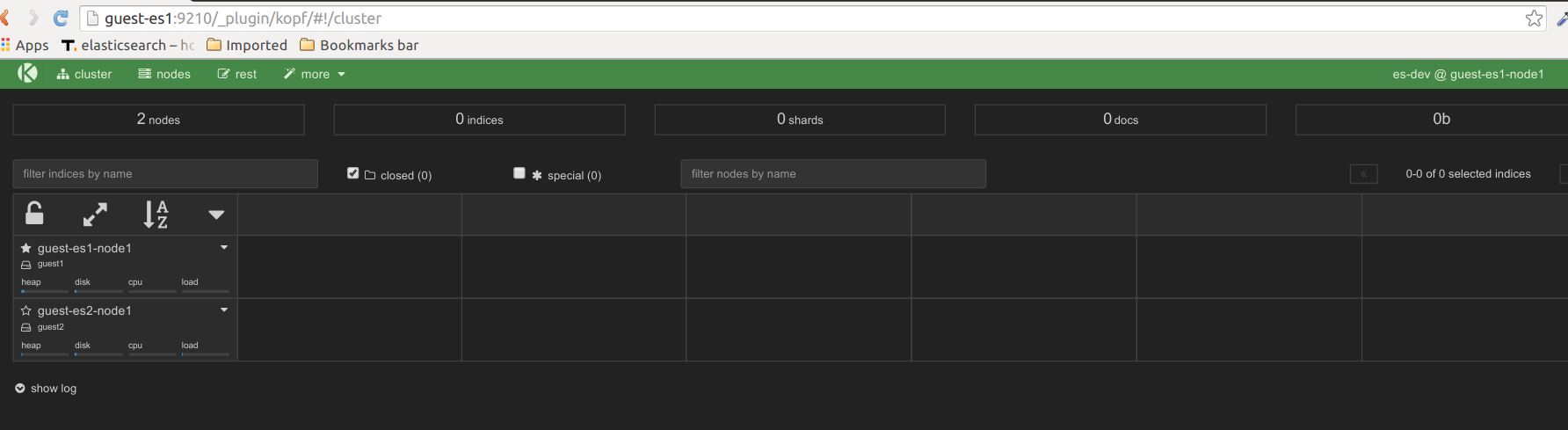
We set up our ‘h1b’ index from the H-1B. The Mechanics by running:
|
1 |
curl -XPOST http://guest-es1:9210/h1b -d @h1b.json |
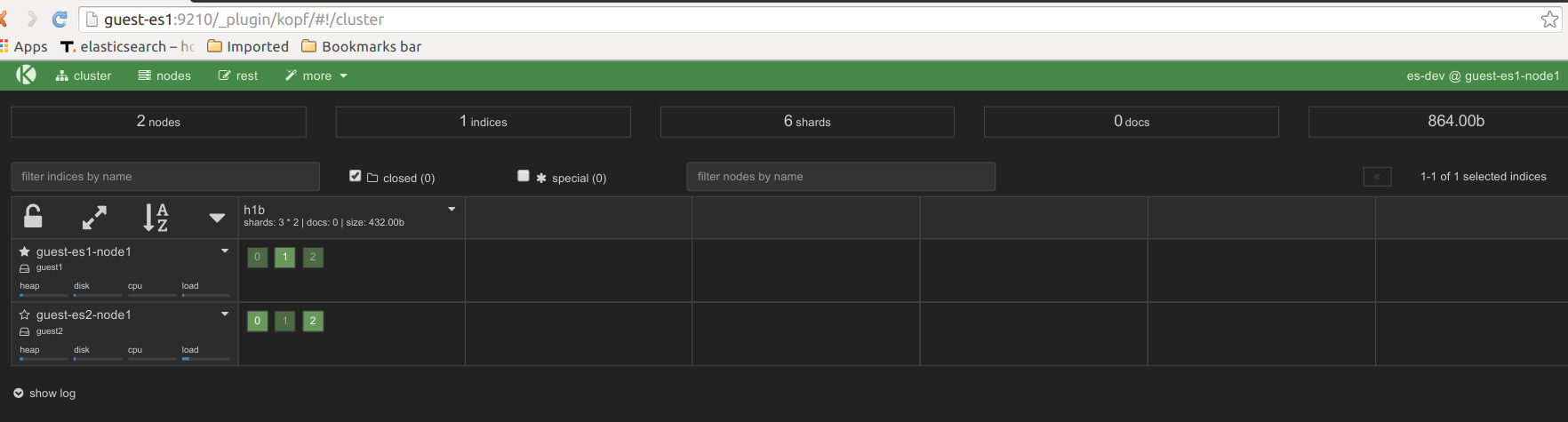
Pointing our indexer on the host to this virtual elastic cluster above and running it shows the document count increasing.
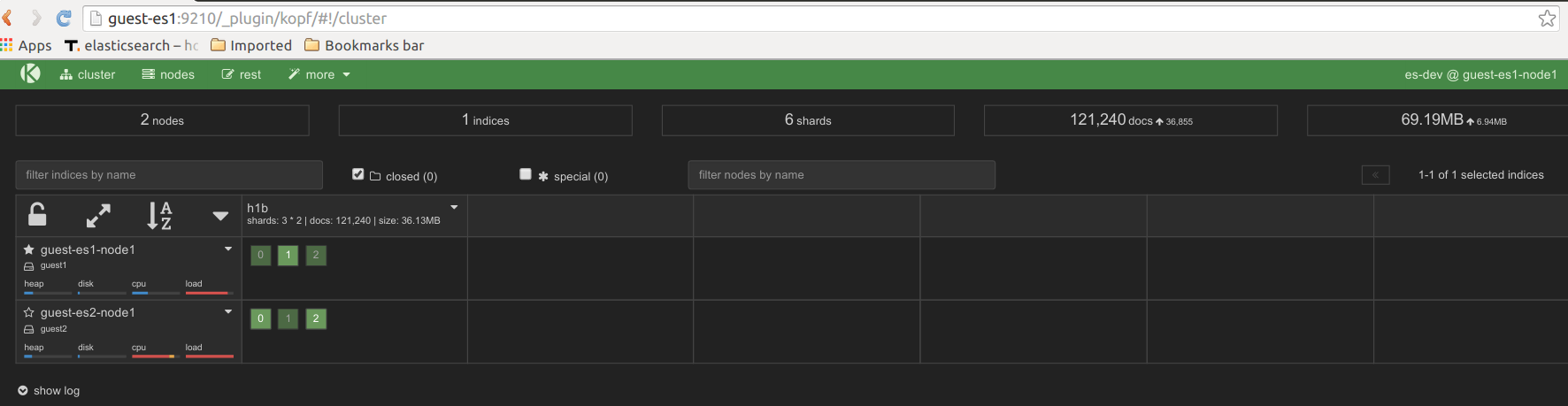
When it is all done we see that we have over 9 millions docs as expected.
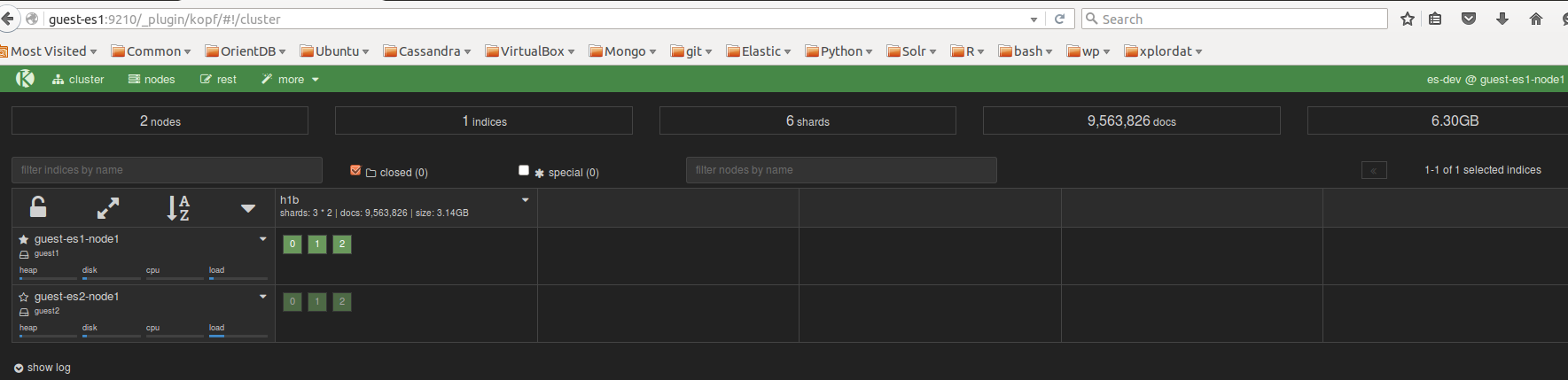
We shut the cluster off by running vagrant halt . Whenever we are ready to work with it again from the host we simply run vagrant up and the cluster will be back up. Success! We have put in place a mechanism to bring up elasticsearch as a service, as needed on a virtual cluster.
That is all for this post. In future posts we will look at extending this to create appliances on AWS so we can do real work. Thanks for reading & feel free to leave a comment if you liked it (or not!)