BERT yields the best F1 scores on three different repositories representing binary, multi-class, and multi-label/class situations. BoW with tf-idf weighted one-hot word vectors using SVM for classification is not a bad alternative to going full bore with BERT however, as it is cheap.
Attention is like tf-idf for deep learning. Both attention and tf-idf boost the importance of some words over others. But while tf-idf weight vectors are static for a set of documents, the attention weight vectors will adapt depending on the particular classification objective. Attention derives larger weights for those words that are influencing the classification objective, thus opening a window into the decision making process with in the deep learning blackbox…
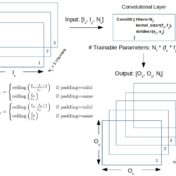
Convolutional layers and their cousins the pooling layers are examined for shape modification and parameter counts as functions of layer parameters in Keras/Tensorflow…
Formulae for trainable parameter counts are developed for a few popular layers as function of layer parameters and input characteristics. The results are then reconciled with what Keras reports upon running the model…
In our last article, we were getting some really good results with CNN when we used a custom text corpus. But will CNN manage to hold onto its lead when it competes with SVM in the battle of sentiment analysis, let’s find that out…
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
Earlier with the bag of words approach we were getting some really good text classification results. But will that hold, when we take into consideration the sequence of words? There is only one way to find out, let’s get right into the action, where we are doing a head on comparison of traditional approach (Naive Bayes) with a modern neural based one (CNN).
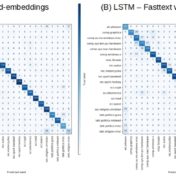
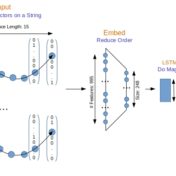
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.