Classification hinges on the notion of similarity. This similarity can be as simple as a categorical feature value such as the color or shape of the objects we are classifying, or a more complex function of all categorical and/or continuous feature values that these objects possess. Documents can be classified… Read more »
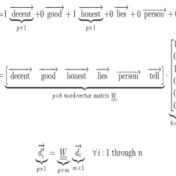
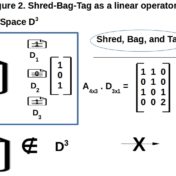
The term-document matrix is a high-order, high-fidelity model for the document-space. High-fidelity in the sense that will correctly shred-bag-tag it to represent it as a vector in term-space as per VSM. has entries, with distinct terms (rows) building documents (columns). But do we need all those values to capture this shred-bag-tag effect of … Read more »
Consider these two one-line documents – “Eat to Live” and “Live to Eat“. They contain the same words, but in different order – leading to a big difference in meaning. Or consider – “Working Hard” & “Hardly Working“. Popular stemmers such as snowball convert ‘Hardly‘ to ‘Hard‘ so that functionally… Read more »
The road to ‘Computational Linguistics Nirvana’ is littered with thesis upon thesis, stacks of journal papers, and volumes of conference proceedings… so one can get lost in a hurry. Whole programs dedicated to computational linguistics have made great advances over the years enabling the Siris and Cortanas of our time. We… Read more »
Ready to write again after an extended break over the holidays and we start off where we left in 2015 with our unfinished quotes… The objective for this post is to assemble the data we need to analyze the nature of quotes in some way, at least in a dry statistical sense to… Read more »
Who does not love a good quote? I had always been a fan myself and collected a bunch over the years. Each morning as I drive kids to school a quote or more spill out as a matter of course. So much so that they started calling me a quote-monster…