
In the previous post we designed the experiment, simulated different operational states and confirmed that the results were as expected – more or less. Here we go over the implementation and a few relevant code snippets before wrapping up this series of posts. As usual the package is available for download at github.
We start with the pom.
1. The pom
Mostly straightforward. The relevant xml snippets are as follows. We use Elasticsearch (6.1.2) for long term storage.
<!-- Kafka packages for producers, consumers and streams --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.0.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>1.0.0</version> </dependency> <!-- Kafka Avro serializers/deserializers --> <dependency> <groupId>io.confluent</groupId> <artifactId>kafka-avro-serializer</artifactId> <version>4.0.0</version> </dependency> <dependency> <groupId>io.confluent</groupId> <artifactId>kafka-streams-avro-serde</artifactId> <version>4.0.0</version> </dependency> <!-- Avro Libraries --> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.8.2</version> </dependency> <!-- Avro code generation --> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.8.2</version> </dependency> <!-- Elasticsearch for long term storage--> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.1.2</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>6.1.2</version> </dependency>
2. Producers
Producers here are the sensors at the vertices A, B, and C. Each sensor produces to an assigned partition: A => 0, B => 1, and C => 2. The sensors throw off raw measurements at a maximum rate of about 1/sec as per the following code snippet running on thread in a loop until interrupted. Lines 5-6 update the position of the vertex. Angular velocity is one revolution per minute (2 PI / 60). Line #7 computes the RawVertex object as per the AVRO spec. Lines 8-9 push the object to the rawVertex topic and wait for full acknowledgement.
while ( !(Thread.currentThread().isInterrupted()) ) {
String key = clientId ;
long currentTime = System.currentTimeMillis() ;
double rand = -error + random.nextDouble() * 2.0 * error ;
valX = valX + amplitude * Math.sin(angularV * (currentTime - timePrev) * 0.001) * rand ;
valY = valY + amplitude * Math.cos(angularV * (currentTime - timePrev) * 0.001) * rand ;
rawVertex = new RawVertex (clientId, currentTime, valX, valY) ;
ProducerRecord<String, RawVertex> record = new ProducerRecord<>(topic, partitionNumber, key, rawVertex) ;
RecordMetadata metadata = producer.send(record).get();
timePrev = currentTime ;
Thread.sleep(1000) ;
}
The important producer configurations in Lines #5, #6 indicate the KafkaAvroSerializers, and Line #7 the url to find/register the schemas.
producerProps.setProperty("acks", "all") ;
producerProps.setProperty("retries", "0") ;
producerProps.setProperty("max.in.flight.requests.per.connection", "1") ;
producerProps.setProperty("bootstrap.servers","localhost:9092") ;
producerProps.setProperty("key.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer") ;
producerProps.setProperty("value.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer") ;
producerProps.setProperty("schema.registry.url","http://localhost:8081") ;
The three producers are started off at the same time via a script (see Section 4) that supplies the initial positions of the vertices.
3. Stream processing
The VertexProcessor and TriangleProcessor work in concert to enable stress metrics on the triangle. A kafka stream is a consumer and/or producer as needed for receiving messages from upstream entities and producing messages to downstream entities. Thus the serialization (for production) & deserialization (for consumption) methodologies need to be defined and be in place before a stream topology can be instantiated. Further, as the processors may employ a variety of stores (key-value and window in our case here), the means to build these stores should be in place as well.
streamProcess.streamProps.setProperty("num.stream.threads","3") ;
streamProcess.streamProps.setProperty("processing.guarantee","at_least_once") ;
streamProcess.streamProps.setProperty("commit.interval.ms","100") ;
streamProcess.streamProps.setProperty("default.timestamp.extractor", StreamTimeStampExtractor.class.getName());
A few key stream properties are shown above. We employ 3 stream threads (Line #1) to match the 3 rawVertex partition sources we have. Line #4 defines the Stream Time, the key quantity that makes the stream move or not. This is the actual measurement time in case of the rawVertex and the average of those in case of the smoothedVertex. The code snippet below shows the custom class that extends TimestampExtractor. Lines #8 and #12 extract the measurement time as the stream-time.
public class StreamTimeStampExtractor implements TimestampExtractor {
public long extract(ConsumerRecord<Object, Object> record, long previousTimestamp) {
long timeStamp = System.currentTimeMillis() ;
Object obj = record.value() ;
if (obj != null) {
if (obj instanceof RawVertex) {
RawVertex rv = (RawVertex) obj ;
timeStamp = rv.getTimeInstant() ;
}
else if (obj instanceof SmoothedVertex) {
SmoothedVertex sv = (SmoothedVertex) obj ;
timeStamp = sv.getTimeInstant() ;
}
}
return timeStamp ;
}
}
3.1 Serialization & Deserialization
The messages in our cases have Strings/Longs as the keys but Avro objects as the values. The following snippet of code configures and returns a serializer/deserializer we will need for the values (Lines 6 and 15 below).
KafkaAvroDeserializer getKafkaAvroDeserializer() {
Map<String, String> kadsConfig = new HashMap<String, String>() ;
kadsConfig.put("schema.registry.url", "http://localhost:8081");
kadsConfig.put("specific.avro.reader", "true") ;
KafkaAvroDeserializer kads = new KafkaAvroDeserializer() ;
kads.configure(kadsConfig, false) ; // false means NOT FOR the key
return kads ;
}
KafkaAvroSerializer getKafkaAvroSerializer() {
Map<String, String> kasConfig = new HashMap<String, String>() ;
kasConfig.put("schema.registry.url", "http://localhost:8081");
kasConfig.put("specific.avro.reader", "true") ;
KafkaAvroSerializer kas = new KafkaAvroSerializer() ;
kas.configure(kasConfig, false) ; // false means NOT for the key
return kas ;
}
Querying the schema registry shows the String, and the RawVertex, SmoothedVertex schemas we defined via “avsc” files in the data model.
curl -X GET http://localhost:8081/subjects
["rawVertex-key","triangle-stress-monitor-rawVertexKVStateStore-changelog-value","triangle-stress-monitor-smoothedVerticesWindowStateStore-changelog-value","smoothedVertex-value","rawVertex-value","triangle-stress-monitor-smoothedVertexKVStateStore-changelog-value"]
curl -X GET http://localhost:8081/schemas/ids/1
{"schema":"\"string\""}
curl -X GET http://localhost:8081/schemas/ids/2
{"schema":"{\"type\":\"record\",\"name\":\"RawVertex\",\"namespace\":\"com.xplordat.rtmonitoring.avro\",\"fields\":[{\"name\":\"sensor\",\"type\":{\"type\":\"string\",\"avro.java.string\":\"String\"}},{\"name\":\"timeInstant\",\"type\":\"long\"},{\"name\":\"X\",\"type\":\"double\"},{\"name\":\"Y\",\"type\":\"double\"}]}"}
curl -X GET http://localhost:8081/schemas/ids/3
{"schema":"{\"type\":\"record\",\"name\":\"SmoothedVertex\",\"namespace\":\"com.xplordat.rtmonitoring.avro\",\"fields\":[{\"name\":\"sensor\",\"type\":{\"type\":\"string\",\"avro.java.string\":\"String\"}},{\"name\":\"timeStart\",\"type\":\"long\"},{\"name\":\"timeInstant\",\"type\":\"long\"},{\"name\":\"timeEnd\",\"type\":\"long\"},{\"name\":\"X\",\"type\":\"double\"},{\"name\":\"Y\",\"type\":\"double\"},{\"name\":\"numberOfSamplesIntheAverage\",\"type\":\"long\"},{\"name\":\"cumulativeDisplacementForThisSensor\",\"type\":\"double\"},{\"name\":\"pushCount\",\"type\":\"long\"},{\"name\":\"pushTime\",\"type\":\"long\"}]}"}
3.2 The Stores
The VertexProcessor employs two local stores for resiliency. One of them holds (Line #10 below), the current batch of raw vertices being smoothed. In case the processor dies, the restarted processor will read the current state from this store. The other (Line #11) will have the previously smoothed vertex object, which is needed for computing cumulative displacement of the vertex. The windowstore used by the TriangleProcessor is defined in Line #14, with two parameters – the length of the time-window, and its retention time. The right values for these depend on the overall beat of the apparatus – the production rate, expected delays in transit, a reasonable duration to average the measurements over etc… that we discussed at length in the previous post.
Map<String, String> schemaConfig = Collections.singletonMap("schema.registry.url", "http://localhost:8081");
Serde<RawVertex> rawVertexAvroSerde = new SpecificAvroSerde<>() ;
rawVertexAvroSerde.configure(schemaConfig, false) ; // This "false" is for the variable "final boolean isSerdeForRecordKeys"
Serde<SmoothedVertex> smoothedVertexAvroSerde = new SpecificAvroSerde<>() ;
smoothedVertexAvroSerde.configure(schemaConfig, false) ; // This "false" is for the variable "final boolean isSerdeForRecordKeys"
// Local stores used by VertexProcessor
StoreBuilder<KeyValueStore<Long, RawVertex>> vertexProcessorRawVertexKVStateStoreBuilder = Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore("rawVertexKVStateStore"), Serdes.Long(), rawVertexAvroSerde) ;
StoreBuilder<KeyValueStore<Long, SmoothedVertex>> vertexProcessorSmoothedVertexKVStateStoreBuilder = Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore("smoothedVertexKVStateStore"), Serdes.Long(), smoothedVertexAvroSerde) ;
// Local Window Store used by TriangleProcessor
StoreBuilder<WindowStore<String, SmoothedVertex>> triangleProcessorWindowStateStoreBuilder = Stores.windowStoreBuilder(Stores.persistentWindowStore("smoothedVerticesWindowStateStore", TimeUnit.MINUTES.toMillis(windowRetentionMinutes), 3, TimeUnit.SECONDS.toMillis(windowSizeSeconds),false), Serdes.String(), smoothedVertexAvroSerde) ;
3.3 The Topology
The process topology described in the earlier posts is materialized by the following code snippet.
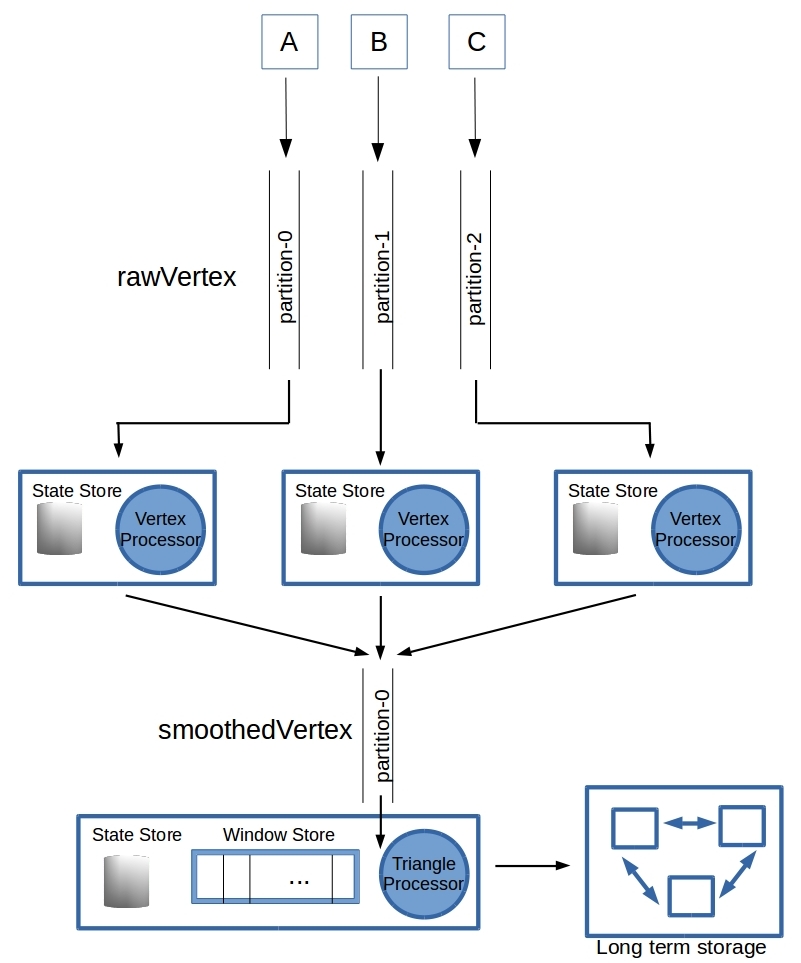{kind=link}
Topology topology = new Topology();
topology.addSource("vertexSource", new StringDeserializer(), getKafkaAvroDeserializer(), "rawVertex")
.addProcessor("vertexProcessor", () -> new VertexProcessor(smoothingIntervalSeconds, resetStores), "vertexSource")
.addStateStore(vertexProcessorRawVertexKVStateStoreBuilder, "vertexProcessor")
.addStateStore(vertexProcessorSmoothedVertexKVStateStoreBuilder, "vertexProcessor")
.addSink("smoothedVerticesSink", "smoothedVertex", new StringSerializer(), getKafkaAvroSerializer(), "vertexProcessor")
.addSource("smoothedVerticesSource", new StringDeserializer(), getKafkaAvroDeserializer(), "smoothedVertex")
.addProcessor("triangleProcessor", () -> new TriangleProcessor(windowSizeSeconds, windowRetentionMinutes, resetStores, smoothedIndex, triangeIndex), "smoothedVerticesSource")
.addStateStore(triangleProcessorWindowStateStoreBuilder, "triangleProcessor") ;
In Line #3 the data is read off of the “rawVertex” topic with the configured deserializers (String for key & KafkaAvro for the value which is a RawVertex object). This flows into the VertexProcessor in Line #4 that smooths them over a short time-interval before forwarding the average into “smoothedVertex” topic in Line #7. The smoothedVertex topic serves as the source (Line #8) for the TriangleProcessor in Line #8. The topology built and executed by Kafka is obtained with topology.describe() showing two sub-topologies as expected – excellent!
Sub-topology: 0
Source: smoothedVerticesSource (topics: [smoothedVertex])
--> triangleProcessor
Processor: triangleProcessor (stores: [smoothedVerticesWindowStateStore])
--> none
<-- smoothedVerticesSource
Sub-topology: 1
Source: vertexSource (topics: [rawVertex])
--> vertexProcessor
Processor: vertexProcessor (stores: [smoothedVertexKVStateStore, rawVertexKVStateStore])
--> smoothedVerticesSink
<-- vertexSource
Sink: smoothedVerticesSink (topic: smoothedVertex)
<-- vertexProcessor
When starting a new run we may want to cleanup any hold over stores from a previous run. In case of a crash and restart we should not reset the stores, of course. This is Line #3 below. In case of a failure or interruption a shutdown hook allows for all the state stores to be closed cleanly in Line #12.
KafkaStreams kstreams = new KafkaStreams(topology, streamProps);
if (resetStores) {
kstreams.cleanUp();
}
kstreams.start() ;
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
try {
logger.error ("Interrupting stream processing...") ;
kstreams.close() ;
}
catch (Exception e) {
logger.error ("Errors in shutdownhook..." + e) ;
System.exit(1) ;
}
}
}) ;
The Vertex and Triangle processors provide an implementation for kstreams.close() to take care of any other house keeping operations. For example the TriangleProcessor (see Section 3.5) employs the following snippet to flush the triangle metrics and smoothed vertex measurements to Elasticsearch before exiting.
@Override
public void close() {
if (smoothedVertexDocs.size() > 0) {
indexThis (smoothedVertexDocs, smoothedIndex) ;
}
if (triangleDocs.size() > 0) {
indexThis (triangleDocs, triangleIndex) ;
}
smoothedVerticesWindowStateStore.close();
}
3.4 The VertexProcessor
The VertexProcessor averages the incoming raw measurements over the smoothing interval and forwards the smoothedVertex to the next stage. The stores are initialized in Lines 3-4 below. In Line # 5, the punctuation is scheduled to run periodically at an interval – smoothingInterval (12 seconds in our simulaions). The smoothed vertex is computed (Line # 14), forwarded downstream (Line #15), and also saved to local store (Line # 17). We get ready for a new smoothing batch in Line #16.
public void init(ProcessorContext context) {
this.context = context;
rawVertexKVStateStore = (KeyValueStore) context.getStateStore("rawVertexKVStateStore");
smoothedVertexKVStateStore = (KeyValueStore) context.getStateStore("smoothedVertexKVStateStore");
context.schedule(smoothingInterval, PunctuationType.STREAM_TIME, (timestamp) -> {
if (numberOfSamplesIntheAverage > 0L) {
SmoothedVertex prevLsv = smoothedVertexKVStateStore.get(1L) ;
double prevX = prevLsv.getX() ;
double prevY = prevLsv.getY() ;
pushCount = prevLsv.getPushCount() + 1 ;
double X = xSum / numberOfSamplesIntheAverage ;
double Y = ySum / numberOfSamplesIntheAverage ;
double cumulativeDisplacementForThisSensor = prevLsv.getCumulativeDisplacementForThisSensor() + findLength (X, Y, prevX, prevY) ;
SmoothedVertex sv = new SmoothedVertex (sensor, timeStart, timeInstant, timeEnd, X, Y, numberOfSamplesIntheAverage, cumulativeDisplacementForThisSensor, pushCount, System.currentTimeMillis()) ;
context.forward(sensor, sv) ; // Forward it to "smoothedVertex" topic.
startASmoothingBatch = true ;
smoothedVertexKVStateStore.put(1L, sv) ; // Update the smoothedVertexKVStateStore
context.commit();
}
});
}
In case of failure & restart we need to load the store from disk and initialize the state (Line #3 below). An iterator over the store in Line #17 provides access to the raw vertex objects that have been pulled off the topic prior to failure but not yet processed into the smoothedVertex topic.
if (!(resetStores)) { // need to restore the state from disk...
startASmoothingBatch = false ;
restoreFromStore() ;
}
void restoreFromStore() {
numberOfSamplesIntheAverage = 0L ;
KeyValueIterator<Long, RawVertex> iter0 = rawVertexKVStateStore.all();
xSum = 0.0 ; ySum = 0.0 ;
while (iter0.hasNext()) {
RawVertex rv = iter0.next().value ;
xSum = xSum + rv.getX() ; ySum = ySum + rv.getY() ;
timeStart = Math.min(timeStart, rv.getTimeInstant()) ;
timeEnd = Math.max(timeEnd, rv.getTimeInstant()) ;
numberOfSamplesIntheAverage++ ;
}
iter0.close() ;
}
3.5 The TriangleProcessor
The TriangleProcessor gets the forwarded smoothedVertex objects from the VertexProcessors, computes triangle metrics as soon as a window gets at least one of A, B, and C measurements. The metrics are saves it to an elasticsearch index for long term storage. Line #3 in the code below keeps track of the ‘travel-time’ that we plotted in the previous post. This is the time that a smoothed vertex takes to reach the TriangleProcessor after it has been forwarded by the VertexProcessor. If we are restarting the stream processor after a crash, Line #9 gets engaged and reads in all the available windowstore data. Line #13 saves the incoming measurement to the window store.
Because the time-windows have defined boundaries (first window; [0, windowSize), second window: [windowSize, 2*windowSize), etc…) we know which window an incoming measurement will fall into. This is Line #15, followed by keeping track of this window (Line #13) for “saturation-time” that we want to know. How long does a time-window needs to be retained will depend on the maximum saturation-time that we can expect in a simulation. We talked about this a good bit in the previous post. Every time a window gets a new measurement and it has at least one each of A, B, and C, we compute the triangle metrics – this is Line #26.
public void process (String key, SmoothedVertex value) {
long arrivalTime = System.currentTimeMillis() ;
long delay = arrivalTime - value.getPushTime() ;
long measurementTime = value.getTimeInstant() ;
String incomingSensor = value.getSensor() ;
if (isThisANewProcessor) {
if (!(resetStores)) {
restoreFromStore(value.getTimeStart()) ;
}
isThisANewProcessor = false ; // the above block executes just once upon start up
}
smoothedVerticesWindowStateStore.put(incomingSensor, value, measurementTime) ;
long windowKey = (measurementTime / windowSize) * windowSize ;
if (!(windowCounts.containsKey(windowKey))) {
initializeWindow (windowKey, arrivalTime) ;
}
HashMap<String, Long> hm = windowCounts.get(windowKey) ;
hm.put(incomingSensor, hm.get(incomingSensor) + 1L) ;
hm.put("total", hm.get("total") + 1) ;
hm.put("latestArrivalWallClockTime", arrivalTime) ;
windowCounts.put(windowKey, hm) ;
if ( (hm.get("A") > 0) && (hm.get("B") > 0) && (hm.get("C") > 0) ) {
computeTriangleMetrics (windowKey) ;
}
}
In the code snippet below, the vertex coordinates in a window are processed to produce a single value for A, B & C and at a mean time. Line #3 gets an iterator over all the smoothedVertex objects in a given time-window.
ArrayList<SmoothedVertex> getItemsInWindow (String sensor, long timeStart, long timeEnd) {
ArrayList<SmoothedVertex> windowedData = new ArrayList<SmoothedVertex>() ;
WindowStoreIterator<SmoothedVertex> iter = smoothedVerticesWindowStateStore.fetch(sensor, timeStart, timeEnd) ;
while (iter.hasNext()) {
windowedData.add(iter.next().value) ;
}
iter.close();
return windowedData ;
}
int aCount = 0 ; int bCount = 0 ; int cCount = 0 ; long time = 0L ;
double ax = 0.0 ; double ay = 0.0 ; double bx = 0.0 ; double by = 0.0 ; double cx = 0.0 ; double cy = 0.0 ;
double aDisplacement = 0.0 ; double bDisplacement = 0.0 ; double cDisplacement = 0.0 ;
for (String sensor: allSensors) {
Iterator<SmoothedVertex> itr = getItemsInWindow(sensor, windowTimeStart, windowTimeEnd).iterator() ;
while (itr.hasNext()) {
SmoothedVertex sv = itr.next() ;
time = time + sv.getTimeInstant() ;
if (sensor.equals("A")) {
ax = ax + sv.getX() ;
ay = ay + sv.getY() ;
aDisplacement = aDisplacement + sv.getCumulativeDisplacementForThisSensor() ;
aCount++ ;
}
else if (sensor.equals("B")) {
bx = bx + sv.getX() ;
by = by + sv.getY() ;
bDisplacement = bDisplacement + sv.getCumulativeDisplacementForThisSensor() ;
bCount++ ;
}
else if (sensor.equals("C")) {
cx = cx + sv.getX() ;
cy = cy + sv.getY() ;
cDisplacement = cDisplacement + sv.getCumulativeDisplacementForThisSensor() ;
cCount++ ;
}
}
}
With a triangle at hand we proceed forward to compute the metrics, and save it to Elasticsearch for long term storage. Any alerts based on the computed metrics will be injected here – but we will not delve into that. Line #12 computes the time gap between the earliest & latest arriving measurements in a window – so we can get a distribution of the this quantity over time and use it to adjust the window retention time.
if ( (aCount >= 1) && (bCount >= 1) && (cCount >= 1) ) {
ax = ax / aCount ; ay = ay / aCount ; bx = bx / bCount ; by = by / bCount ; cx = cx / cCount ; cy = cy / cCount ;
aDisplacement = aDisplacement / aCount ; bDisplacement = bDisplacement / bCount ; cDisplacement = cDisplacement / cCount ;
long timeInstant = time / (aCount + bCount + cCount) ;
double totalDisplacement = aDisplacement + bDisplacement + cDisplacement ;
double AB = findLength (ax, ay, bx, by) ;
double BC = findLength (bx, by, cx, cy) ;
double AC = findLength (ax, ay, cx, cy) ;
double perimeter = AB + BC + AC ;
double halfPerimeter = perimeter * 0.5 ;
double area = Math.sqrt (halfPerimeter*(halfPerimeter-AB)*(halfPerimeter-BC)*(halfPerimeter-AC)) ;
long wallclock_span = windowCounts.get(windowKey).get("latestArrivalWallClockTime") - windowCounts.get(windowKey).get("earliestArrivalWallClockTime") ;
}
4. Running The Simulation
First the rawVertex topic is created with 3 partitions and the smoothedVertex topic with 1 partition.
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic rawVertex $KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic smoothedVertex
The three producers are started off from a script that provides all the producer configs (Section 2) as arguments. The production parameters are geared (no retries, synchronous send, only one message in flight, full acknowledgement etc…) towards keeping the message order in the topic to be identical to production order – we count on this for smoothing in the VertexProcessor.
#!/bin/bash
function monitor() {
clientId=$1 # A or B or C. The names of the Vertices
acks=$2 # We use "all" for complete acknowledgement
retries=$3 # No retries, as we want ordered delivery
enableIdempotence=$4
maxInFlightRequestsPerConnection=$5 # 1 as we want ordered delivery
sync=$6 # wait for send action to complete
topics=$7 # rawVertex
sleepTimeMillis=$8 # 1000
amplitude=$9 # 1
# 2.0 * Math.PI * angularV / 60.0 => It will take 60secs i.e. 1 minute to trace the full circle. => period = 1 min
angularV=${10} # 1
error=${11} # 0.001
xReference=${12} # Starting X position for this vertex
yReference=${13} # Starting Y position for this vertex
java -cp ./core/target/rtmonitoring.jar com.xplordat.rtmonitoring.Producers $clientId $acks $retries $enableIdempotence $maxInFlightRequestsPerConnection $sync $topics $sleepTimeMillis $amplitude $angularV $error $xReference $yReference
}
monitor A all 0 false 1 true rawVertex 1000 1.0 1.0 0.001 0.0 0.0 &
monitor B all 0 false 1 true rawVertex 1000 1.0 1.0 0.001 1.0 0.0 &
monitor C all 0 false 1 true rawVertex 1000 1.0 1.0 0.001 0.5 0.866 &
Likewise the stream processor is started (or re-started) with a script supplying the various config parameters indicated in Section 3.
#!/bin/bash
startStream=$1
if [ "$startStream" == "start" ]; then
resetStores="true"
elif [ "$startStream" == "resume" ]; then
resetStores="false"
else
echo "Need 1 arg start/resume"
exit
fi
streamProcess() {
applicationId=$1
clientId=$2
nthreads=$3
guarantee=$4 # at_least_once
commit_interval_ms=$5 # 100
resetStores=$6
windowSize=$7 # seconds
windowRetention=$8 # minutes
smoothIngInterval=$9 # seconds
smoothedIndex=${10}
triangleIndex=${11}
java -cp ./core/target/rtmonitoring.jar com.xplordat.rtmonitoring.StreamProcess $applicationId $clientId $nthreads $guarantee $commit_interval_ms $resetStores $windowSize $windowRetention $smoothIngInterval $smoothedIndex $triangleIndex
}
streamProcess triangle-stress-monitor 0 3 at_least_once 100 $resetStores 60 360 12 smoothed triangle
5. Conclusion
With that we close this post – and this series of posts on using Kafka for streaming analytics. Hopefully the detail here is all that one needs to replicate the simulations in this series. The complete code is available at github.