Clustering Text with Transformed Document Vectors
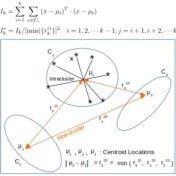
A sister task to classification in machine learning is clustering. While classification requires up-front labeling of training data with class information, clustering is unsupervised. There is a large benefit to unattended grouping of text on disk and we would like to know if word-embeddings can help. In fact, once identified, these… Read more »