Earlier with the bag of words approach we were getting some really good text classification results. But will that hold, when we take into consideration the sequence of words? There is only one way to find out, let’s get right into the action, where we are doing a head on comparison of traditional approach (Naive Bayes) with a modern neural based one (CNN).
For generic text, word bag approaches are very efficient at text classification. For a binary text classification task studied here, LSTM working with word sequences is on par in quality with SVM using tf-idf vectors. But performance is a different matter…
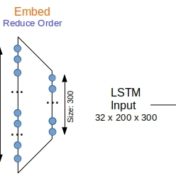
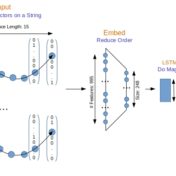
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.