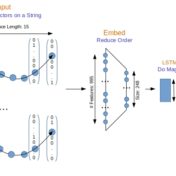
Earlier with the bag of words approach we were getting some really good text classification results. But will that hold, when we take into consideration the sequence of words? There is only one way to find out, let’s get right into the action, where we are doing a head on comparison of traditional approach (Naive Bayes) with a modern neural based one (CNN).
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.
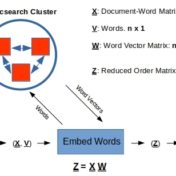
In the previous post Word Embeddings and Document Vectors: Part 1. Similarity we laid the groundwork for using bag-of-words based document vectors in conjunction with word embeddings (pre-trained or custom-trained) for computing document similarity, as a precursor to classification. It seemed that document+word vectors were better at picking up on similarities… Read more »
Closed-form solutions are sweet. No hand-wringing/waving required to make a point. Given the assumptions, the model predictions are exact so we can readily evaluate the impact of assumptions. And, we get the means to evaluate alternate (e.g. numerical) approaches applied to these same limiting cases with the exact solution. We are… Read more »
The curse of dimensionality is the bane of all classification problems. What is the curse of dimensionality? As the number of features (dimensions) increase linearly, the amount of training data required for classification increases exponentially. If the classification is determined by a single feature we need a-priori classification data over… Read more »