Attention is like tf-idf for deep learning. Both attention and tf-idf boost the importance of some words over others. But while tf-idf weight vectors are static for a set of documents, the attention weight vectors will adapt depending on the particular classification objective. Attention derives larger weights for those words that are influencing the classification objective, thus opening a window into the decision making process with in the deep learning blackbox…
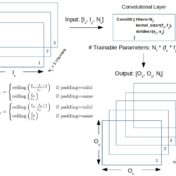
Convolutional layers and their cousins the pooling layers are examined for shape modification and parameter counts as functions of layer parameters in Keras/Tensorflow…
Formulae for trainable parameter counts are developed for a few popular layers as function of layer parameters and input characteristics. The results are then reconciled with what Keras reports upon running the model…
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.