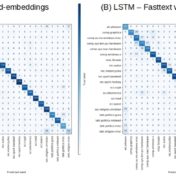
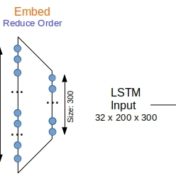
BERT yields the best F1 scores on three different repositories representing binary, multi-class, and multi-label/class situations. BoW with tf-idf weighted one-hot word vectors using SVM for classification is not a bad alternative to going full bore with BERT however, as it is cheap.
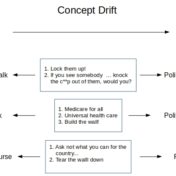
Concept drift is a drift of labels with time for the essentially the same data. It leads to the divergence of decision boundary for new data from that of a model built from earlier data/labels. Scoring randomly sampled new data can detect the drift allowing us to trigger the expensive re-label/re-train tasks on an as needed basis…
In our last article, we were getting some really good results with CNN when we used a custom text corpus. But will CNN manage to hold onto its lead when it competes with SVM in the battle of sentiment analysis, let’s find that out…
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
For generic text, word bag approaches are very efficient at text classification. For a binary text classification task studied here, LSTM working with word sequences is on par in quality with SVM using tf-idf vectors. But performance is a different matter…