The words that are significant to a class can be used improve the precision-recall trade off in classification. Using the top significant terms as the vocabulary to drive a classifier yields improved results with a much small sized model for predicting MIMIC-III CCU readmissions from discharge notes
BERT yields the best F1 scores on three different repositories representing binary, multi-class, and multi-label/class situations. BoW with tf-idf weighted one-hot word vectors using SVM for classification is not a bad alternative to going full bore with BERT however, as it is cheap.
Feature space cracking new data introduces potentially useful new classes if detected. Spurts in the rate of increase of new data points with a less than acceptable classification confidence, indicate that new data zones are being carved out in the feature space…
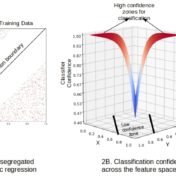
Logistic Regression has traditionally been used as a linear classifier, i.e. when the classes can be separated in the feature space by linear boundaries. That can be remedied however if we happen to have a better idea as to the shape of the decision boundary…
Closed-form solutions are sweet. No hand-wringing/waving required to make a point. Given the assumptions, the model predictions are exact so we can readily evaluate the impact of assumptions. And, we get the means to evaluate alternate (e.g. numerical) approaches applied to these same limiting cases with the exact solution. We are… Read more »