
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
Document is a specific sequence of words. But not all sequences of words are documents. Teaching the difference to an algorithm is a tall order. Taking the sequence of words into account for text analysis is in general computationally expensive. Deep learning approaches such as LSTM allow us to model a document as a string- of-words and they have indeed found some success in NLP tasks recently.
On the other hand when we shred the document and make bags by word, we end up with a vector of weights/counts of these words. The mapping from a document to this vector can be many-to-one as all possible sequences of words yield the same vector. So the deciphering of the meaning of the original document (much less resurrecting it!), from this vector is not possible. Nevertheless this decades old bags-of-words approach to modeling documents has been the main stay for NLP tasks.
When the sequence of words is important in determining the class of a document, string-of-words approaches will outshine the bags-of-words. We have demonstrated this with synthetic documents where LSTM trounced the bags-of-words approach (Naive Bayes working with tf-idf vectors) for classification. But for a real text corpus of movie reviews for binary sentiment classification, we have shown that both LSTM and SVM (with tf-idf vectors) were comparable in quality even while the former took much longer.
The objective of this post is to further evaluate “bags vs strings” for a multiclass situation. We will work with the 20-newsgroups text corpus that is available from scikit-learn api. We will also look at the impact of using word-embeddings – both pre-trained and custom. We go through some code snippets here, but the complete code to reproduce the results can be downloaded from github.
1. Tokenize the 20news Corpus
This corpus consists of posts made to 20 news groups so they are well-labeled. There are over 18000 posts that are more or less evenly distributed across the 20 topics. In the code snippet below we fetch these posts, clean and tokenize them to get ready for classification.
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
nltk_stopw = stopwords.words('english')
def tokenize (text): # no punctuation & starts with a letter & between 3-15 characters in length
tokens = [word.strip(string.punctuation) for word in RegexpTokenizer(r'\b[a-zA-Z][a-zA-Z0-9]{2,14}\b').tokenize(text)]
return [f.lower() for f in tokens if f and f.lower() not in nltk_stopw]
def get20News():
X, labels, labelToName = [], [], {}
twenty_news = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), shuffle=True, random_state=42)
for i, article in enumerate(twenty_news['data']):
stopped = tokenize (article)
if (len(stopped) == 0):
continue
groupIndex = twenty_news['target'][i]
X.append(stopped)
labels.append(groupIndex)
labelToName[groupIndex] = twenty_news['target_names'][groupIndex]
nTokens = [len(x) for x in X]
return X, np.array(labels), labelToName, nTokens- Lines #9 – 10. Tokenization. Remove all punctuation and NLTK stop words. Make sure all words/tokens start with a letter. And only retain those words between 3 and 15 characters long.
- Line #14: Use scikit-learn api to fetch the posts but make sure to remove the “dead give away” clues as to what topic a given post belongs to.
- Line # 23: Taking note of number of words in each document helps us choose a reasonable sequence length for LSTM later. The percentile stats on nTokens shows that over 92% of the documents have less than 200 words in them.
2. Word-Embeddings
Word-embeddings are short (of length p that is much, much shorter than the size of the vocabulary nWords) numerical vector representations for words. They allow us to reduce the dimensionality of the word-space from the length of the corpus vocabulary (about 107, 000 here) to a much shorter length like 300 used here. Pre-trained fasttext word vectors are downloaded, and the custom fasttext ones for the movies corpus are generated offline via Gensim. In either case once in hand they are simply read off of the disk.
# Read the word-embeddings from disk
def getEmbeddingMatrix (word_index, vectorSource):
wordVecSources = {'fasttext' : './vectors/crawl-300d-2M-subword.vec', 'custom_fasttext' : './vectors/' + wordCorpus + '-fasttext.json' }
f = open (wordVecSources[vectorSource])
allWv = {}
if (vectorSource == 'custom_fasttext'):
allWv = json.loads(f.read())
elif (vectorSource == 'fasttext'):
errorCount = 0
for line in f:
values = line.split()
word = values[0].strip()
try:
wv = np.asarray(values[1:], dtype='float32')
if (len(wv) != 300):
errorCount = errorCount + 1
continue
except:
errorCount = errorCount + 1
continue
allWv[word] = wv
print ("# Bad Word Vectors:", errorCount)
f.close()
embedding_matrix = np.zeros((len(word_index)+1, 300)) # +1 for the masked 0 in keras/lstm. Does not affect tf-idf/svm
for word, i in word_index.items():
if word in allWv:
embedding_matrix[i] = allWv[word]
return embedding_matrix- Lines #7 – 8: We have the custom Gensim generated word vectors in a json file structured as { word : vector, ..} so we simply read it off as a dictionary
- Lines #9 – 22: In case of pre-trained vectors, we read the downloaded file, and process with some error checking.
- Lines #26-28: Prepare the nWords x 300 embedding matrix where each row represents the 300 long numerical vector for the corresponding word.
The end result is a matrix where each row represents a 300 long vector for a word. The words/rows are ordered as per the integer index in the word_index dictionary – {word:index}. In case of Keras, the words are ordered based on their frequency. In case of tf-idf vectorizer a word gets its index based on its alphabetical order in the vocabulary. Just book keeping, nothing complex.
3. Pack Bags and Sequences
LSTM works with word sequences as input while the traditional classifiers work with word bags such as tf-idf vectors. Having each document in hand as a list of tokens we are ready for either.
3.1 Tf-Idf Vectors for SVM
We use scikit-learn Tf-Idf Vectorizer to build the vocabulary (the word_index dict variable in Line #7 below) and the document vectors (Line #8) from the tokens.
# Obtain the vocabulary and tf-idf vectors for SVM
from sklearn.feature_extraction.text import TfidfVectorizer
X, labels, labelToName, nTokens = get20News()
X=np.array([np.array(xi) for xi in X]) # rows: Docs. columns: words
vectorizer = TfidfVectorizer(analyzer=lambda x: x, min_df=1).fit(X)
word_index = vectorizer.vocabulary_
Xencoded = vectorizer.transform(X)Xencoded is a sparse nDocs x nWords matrix. When using word-embeddings we convert that to a dense nDocs x 300 matrix by multiplying with the embedding matrix we computed in Section 2. These shorter 300-long dense vectors are then classified.
![\[\underbrace{Xencoded}_{nDocs \times 300} = \underbrace{Xencoded}_{nDocs \times nWords} \, \cdot \, \underbrace{embeddingMatrix}_{nWords \times 300}\]](https://xplordat.com/wp-content/ql-cache/quicklatex.com-7f66746abefc1a761ef93b14a8420c38_l3.png "Rendered by QuickLaTeX.com")
# Turn Xencoded into nWords x 300 dense matrix
def sparseMultiply (sparseX, embedding_matrix):
denseZ = []
for row in sparseX:
newRow = np.zeros(300)
for nonzeroLocation, value in list(zip(row.indices, row.data)):
newRow = newRow + value * embedding_matrix[nonzeroLocation]
denseZ.append(newRow)
denseZ = np.array([np.array(xi) for xi in denseZ])
return denseZ
if (vectorSource != 'none'):
embedding_matrix = getEmbeddingMatrix (word_index, vectorSource)
Xencoded = sparseMultiply (Xencoded, embedding_matrix)3.2 Sequences for LSTM
The text processor in Keras turns each document into a sequence/string of integers, where the integer value indicates the actual word as per the {word:index} dictionary that the same processing generates. The index values start at 1, skipping 0 which is reserved for padding. We use 200-long sequences as the stats on the tokens show that over 92% of the documents have less than 200 words. In Line # 8 in the code below, the documents with fewer than 200 words are ‘post’ padded with the index value 0 that is ignored by the embedding layer (mask_zero=True is set for in the definition of embedding layer in Section 4).
# Turn text into 200-long integer sequences, padding with 0 if necessary to maintain the length at 200
import keras
sequenceLength = 200
kTokenizer = keras.preprocessing.text.Tokenizer()
kTokenizer.fit_on_texts(X)
encoded_docs = kTokenizer.texts_to_sequences(X)
Xencoded = keras.preprocessing.sequence.pad_sequences(encoded_docs, maxlen=sequenceLength, padding='post')4. Models
LSTM is implemented via Keras while SVM is implemented via scikit-learn. Both work with the same train/test split so a comparison would be fair. Twenty percent of the overall corpus (i.e 3660 documents) are set aside for test while training on the remaining 14636 documents.
# Test/Train Split
from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=1).split(Xencoded, labels)
train_indices, test_indices = next(sss)
train_x, test_x = Xencoded[train_indices], Xencoded[test_indices]4.1 LSTM
As in the earlier articles in this series, we use the simplest possible LSTM model, with an embedding layer, one LSTM layer and the output layer. When using external word-embeddings the embedding layer will not be trained i.e., the weights will be what we have read from the disk in Section 2.
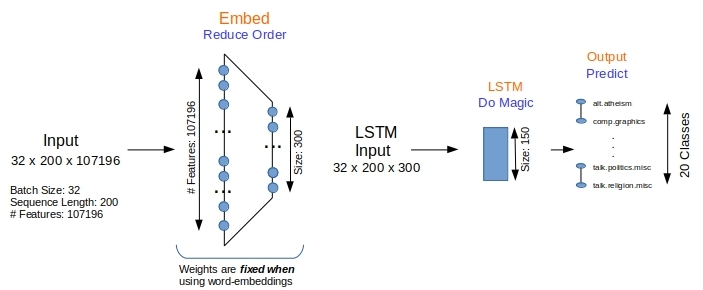
The embedding layer in Figure 1 reduces the number of features from 107196 (the number of unique words in the corpus) to 300. The LSTM layer outputs a 150-long vector that is fed to the output layer for classification. The model itself is defined quite simply below.
- Lines #4 – 8: Embedding layer is trained only when not using external word-embeddings.
- Line #10: The dropout fields are to help with preventing overfitting
# A simple LSTM model
model = keras.models.Sequential()
if (vectorSource != 'none'):
embedding_matrix = getEmbeddingMatrix (kTokenizer.word_index, vectorSource)
embedding = keras.layers.embeddings.Embedding(input_dim=len(kTokenizer.word_index)+1, output_dim=300, weights=[embedding_matrix], input_length=sequenceLength, trainable=False, mask_zero=True)
else:
embedding = keras.layers.embeddings.Embedding(input_dim=len(kTokenizer.word_index)+1, output_dim=300, input_length=sequenceLength, trainable=True, mask_zero=True)
model.add(embedding)
model.add(keras.layers.LSTM(units=150, dropout=0.2, recurrent_dropout=0.2, return_sequences=False))
model.add(keras.layers.Dense(numClasses, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])Training is done with early stopping to prevent over training in Line #6 in the code below. The final output layer yields a vector that is as long as the number of labels, and the argmax of that vector is the predicted class label.
# Train and predict with LSTM
train_labels = keras.utils.to_categorical(labels[train_indices], len(labelToName))
test_labels = keras.utils.to_categorical(labels[test_indices], len(labelToName))
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=5, verbose=2, mode='auto', restore_best_weights=False)
history = model.fit(x=train_x, y=train_labels, epochs=50, batch_size=32, shuffle=True, validation_data = (test_x, test_labels), verbose=2, callbacks=[early_stop])
predicted = model.predict(test_x, verbose=2)
predicted_labels = predicted.argmax(axis=1)4.2 SVM
The model for SVM is much less involved as there are far fewer moving parts and parameters to decide upon. That is always a good thing of course.
# Train and Predict with SVM
from sklearn.svm import LinearSVC
model = LinearSVC(tol=1.0e-6,max_iter=5000,verbose=1)
train_labels = labels[train_indices]
test_labels = labels[test_indices]
model.fit(train_x, train_labels)
predicted_labels = model.predict(test_x)5. Simulations
The confusion matrix and the F1-scores obtained are what we are interested in. With the predicted labels in hand from either approach we use scikit-learn API to compute them.
# Get Confusion Matrix and Classification Report
from sklearn.metrics import classification_report, confusion_matrix
print (confusion_matrix(labels[test_indices], predicted_labels))
print (classification_report(labels[test_indices], predicted_labels, digits=4, target_names=namesInLabelOrder))While we have gone through some snippets in different order, the complete code for lstm-20news.py for running LSTM and svm-20news.py for running SVM is on github. As indicated in the earlier articles various random seeds are initialized for repeatability. The simulations are carried out with the help of a shell script below that loops over the variations we are considering.
#!/bin/bash
for clf in lstm svm; do
for vectorSource in custom-fasttext fasttext none; do
filename=" vectorSource"
echo "PYTHONHASHSEED=0 ; pipenv run python ./
vectorSource"
echo "PYTHONHASHSEED=0 ; pipenv run python ./ vectorSource >
vectorSource >  clf-20news.py
clf-20news.py  filename.out"
done
done
filename.out"
done
done5.1 LSTM
The embedding layer should contribute to
107196 * 300 weight parameters + 300 bias parameters = 32159100 params
This matches the number of non-trainable parameters in Line # 11 below for an LSTM run with external word-embeddings.
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 200, 300) 32159100
_________________________________________________________________
lstm_1 (LSTM) (None, 150) 270600
_________________________________________________________________
dense_1 (Dense) (None, 20) 3020
=================================================================
Total params: 32,432,720
Trainable params: 273,620
Non-trainable params: 32,159,100
_________________________________________________________________
None
Train on 14636 samples, validate on 3660 samples
Epoch 1/50
- 224s - loss: 2.5373 - acc: 0.1837 - val_loss: 2.1770 - val_acc: 0.2757
Epoch 2/50
- 223s - loss: 2.1440 - acc: 0.2913 - val_loss: 2.0411 - val_acc: 0.3437
Epoch 3/50
...
...
Epoch 35/50
- 223s - loss: 0.5122 - acc: 0.8351 - val_loss: 0.9211 - val_acc: 0.7295
Epoch 00035: early stopping
...
...
micro avg 0.7295 0.7295 0.7295 3660
macro avg 0.7209 0.7167 0.7137 3660
weighted avg 0.7300 0.7295 0.7255 3660
Time Taken: 7859.074368476868The run takes over 2 hrs, stops due to the early stopping criteria and obtains an F1-score of 0.73. Figure 2 shows the rate of convergence flattening out a good bit by about 20 epochs or so.

5.2 SVM
SVM has far fewer moving parts and it finishes much more quickly as well. With fasttext embeddings, it works with a 18296 x 300 dense matrix (Line# 7 below), and obtains F1-score of 0.68.
X, labels #classes classes 18296 (18296,) 20 ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardwa
re', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med
', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Vocab sparse-Xencoded 107196 (18296, 107196)
# Bad Word Vectors: 1
Dense-Xencoded (18296, 300)
...
...
micro avg 0.6899 0.6899 0.6899 3660
macro avg 0.6757 0.6766 0.6722 3660
weighted avg 0.6835 0.6899 0.6839 3660
Time Taken: 140.83668708801276. Results
We have the results in hand to not only compare bag & sequences for multiclass classification but also the impact of using pre-trained and custom word-embeddings. Figure 3 shows the F1-scores obtained and the time taken in all cases. SVM with direct tf-idf vectors does the best both for quality & performance. Pre-trained word-embeddings help LSTM improve its F1-score. The larger run times for LSTM are expected and they are in line with what we have seen in the earlier articles in this series.

Figure 4 below compares the best confusion matrices obtained by either approach.
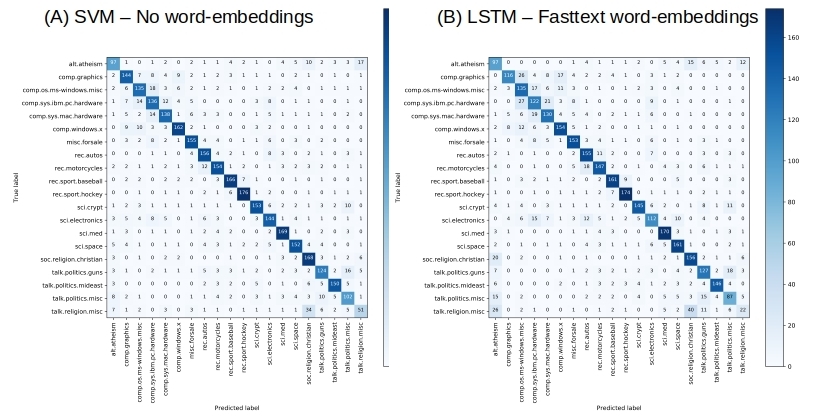
7. Conclusions
So what are we to make of the results obtained in this three part series? For a synthetic text corpus dominated by sequences, word strings beat out word bags handily. For a binary classification task, the score was even. In this multiclass classification task, the scale has tilted towards word bags. Given that the deep learning approaches have so many knobs one can never be sure if the obtained results cannot be improved by tweaking some (which ones, pray tell me… units/layers/batches/cells/… and by how much too… while you are at it…). So here are some loose assessments for whatever they are worth.
- For a real text corpus word bags are tough to beat – especially given the much shorter run times
- Word bag vectors do not really benefit from the use of word-embeddings. We have seen this in earlier articles such as Word Embeddings and Document Vectors: Part 2. Classification
- Word-embeddings can improve the quality of results for word-strings based approaches.
On which environment this code run smoothly? Linux or Windows? Because im still have problem running code on the both environment, even i have been install all the depedencies. Please help
Hi Edy,
I ran it on a linux laptop. Have you cloned the repo from github and followed the instructions there?
What error messages do you get?
Of course i have cloned the repo to my local directory in Linux and followed the instruction, but i got this similar error message “2019-02-16 03:12:49.453982: F tensorflow/core/platform/cpu_feature_guard.cc:37] The TensorFlow library was compiled to use AVX instructions, but these aren’t available on your machine.
Aborted (core dumped)”. Any idea?
Hi Edy,
Googling for that error yields this link https://github.com/tensorflow/tensorflow/issues/24548
where
>> rootkitchao commented on Dec 24, 2018
>> The current version of Tensorflow installed via pip uses the AVX instruction set at compile time.This means that your CPU needs to support the AVX instruction set. This instruction set is supported from the second generation of Intel Core CPUs (codenamed SandyBridge). You can compile a Tensorflow from the source that does not use the AVX instruction set. Or find an already compiled one on the internet.
I believe I am using “version”: “==1.13.1” of tensorflow as per my Pipfile.lock. If you are using a later version try with a lower version perhaps?
Sure, i read about the error code too.. so i will change the deployment on the PC which has newer intel processor. Is it need GPU version of tensorflow?
I will update the progress in next 12hours, thanks very much
i have been deployed the sentiment binary classification smoothly, thanks for guidance. then i want to deploy the multiclass sentiment classification, i will update again later
Excellent!. Glad you are able to make prggress, Edy.
Hello, I have been confused what is missing on the module. when i tried to deploy lstm-20news.py.. i got this error below. please kindly give me instruction to fix it. (FYI, on the vectors folder there is 20news-fasttext.json and crawl-300d-2M-subword.vec)
Using TensorFlw backend.
Traceback (most recent call last):
File “lstm-20news.py”, line 27, in
vectorSource = str(sys.argv[1]) # none, fasttext, custom-fasttext
IndexError: list index out of range
You are perhaps missing the argument. It should be run with a single argument that is one of “none” or “fasttext” or “custom-fasttext”
So run it like:
pipenv run python ./lstm-20news.py none
for example. See the shell script that loops over the 3 possible args and runs it 3 times…
Perfect! I was on training now, i will try the possible three args one by one. I will update soon if finish training. So excuse me to know what is the purpose use thee different args? Which is optional to use one of them. Thanks
Well, we are testing the effectiveness of different word-embeddings on the performance of LSTM for this classification exercise. When the arg is ‘none’ we are asking LSTM to train the embed matrix parameters as part of the overall optimization process while fitting the training data. With the other two arguments we are ‘supplying’ the embed matrix parameters from an external file and telling LSTM to NOT to train for them. And this external file is the one we are reading from disk with vectors (fastext or custom-fastext) for different words. You can take a look at this series of articles
http://xplordat.com/2018/10/09/word-embeddings-and-document-vectors-part-2-classification/
for working with pre-trained or custom word-embeddings.
Very helpful answer, thanks.. i will read it soon
Hello, i have been tried to deploy both LSTM and SVM script, but i think the accuracy need more higher. I got 68-72% accuracy of LSTM and SVM. Does anything i can do to make it better accuracy? Thanks
It depends on the text corpus and the quality of training data… If you have been able to reproduce the reported the results in these blogs then we know that the basic set up is working as expected. Now, when you replace the text corpus with a different one, you will need to experiment with modifying the tokenization perhaps (what kind of documents are these?). First get SVM ‘without’ any embeddings to do the best job it can. That will be the baseline and you will understand any limitations posed by your particular text corpus.
I think i need to change the text corpus with (.txt) document like in this blog post “Sentiment Analysis with Word Bags and Sequence”. I saw it contains of .txt document with separated folder of negative and positive. Because at least i have to classify three class (negative, neutral and positive). Honestly im not familiar with python, so kindly please help.
It is very simple, Edy.
(1) Just make a 3rd folder by the name ‘neutral’ under both ‘test’ & ‘train’ folders.
(2) Place your train & test neutral documents in the corresponding folder.
(3) Once done, the only change you need should be these 2 lines (use the lines below and replace what is there in the file)
X, labels, labelToName = [], [], { 0 : ‘neg’, 1: ‘pos’ , 2:’neutral’}
for classIndex, directory in enumerate([‘neg’, ‘pos’, ‘neutral’]):
in the function ‘getMovies’
Should work
I got it, thanks so much
hello, Sir. i sent a message through linkedin messagebox. please kindly check