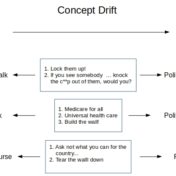
Concept drift is a drift of labels with time for the essentially the same data. It leads to the divergence of decision boundary for new data from that of a model built from earlier data/labels. Scoring randomly sampled new data can detect the drift allowing us to trigger the expensive re-label/re-train tasks on an as needed basis…
Logistic Regression has traditionally been used as a linear classifier, i.e. when the classes can be separated in the feature space by linear boundaries. That can be remedied however if we happen to have a better idea as to the shape of the decision boundary…
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
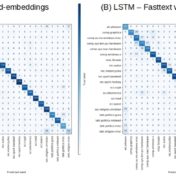
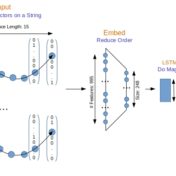
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.
Tf-idf vectors with word-embeddings are analyzed for clustering effectiveness. The text corpus examples considered here indicate that custom word-embeddings can help with clustering
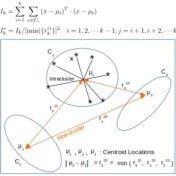
Ok, that was in jest, my apologies! But it is a question we should ask ourselves before embarking on a clustering exercise. Clustering hinges on the notion of distance. The members of a cluster are expected to be closer to that cluster’s centroid than they are to the centroids of other clusters…. Read more »
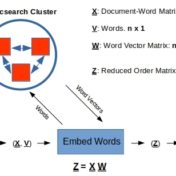
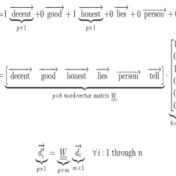
In the previous post Word Embeddings and Document Vectors: Part 1. Similarity we laid the groundwork for using bag-of-words based document vectors in conjunction with word embeddings (pre-trained or custom-trained) for computing document similarity, as a precursor to classification. It seemed that document+word vectors were better at picking up on similarities… Read more »
Classification hinges on the notion of similarity. This similarity can be as simple as a categorical feature value such as the color or shape of the objects we are classifying, or a more complex function of all categorical and/or continuous feature values that these objects possess. Documents can be classified… Read more »
Closed-form solutions are sweet. No hand-wringing/waving required to make a point. Given the assumptions, the model predictions are exact so we can readily evaluate the impact of assumptions. And, we get the means to evaluate alternate (e.g. numerical) approaches applied to these same limiting cases with the exact solution. We are… Read more »
The curse of dimensionality is the bane of all classification problems. What is the curse of dimensionality? As the number of features (dimensions) increase linearly, the amount of training data required for classification increases exponentially. If the classification is determined by a single feature we need a-priori classification data over… Read more »