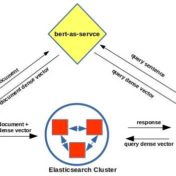
Semantic search at scale is made possible with the advent of tools like BERT, bert-as-service, and of course support for dense vector manipulations in Elasticsearch. While the degree may vary depending on the use case, the search results can certainly benefit from augmenting the keyword based results with the semantic ones…
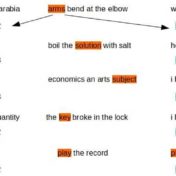
Word vectors have evolved over the years to know the difference between “record the play” vs “play the record”. They have evolved from a one-hot world where every word was orthogonal to every other word, to a place where word vectors morph to suit the context. Slapping a BoW on word vectors is the usual way to build a document vector for tasks such as classification. But BERT does not need a BoW as the vector shooting out of the top [CLS] token is already primed for the specific classification objective
Attention is like tf-idf for deep learning. Both attention and tf-idf boost the importance of some words over others. But while tf-idf weight vectors are static for a set of documents, the attention weight vectors will adapt depending on the particular classification objective. Attention derives larger weights for those words that are influencing the classification objective, thus opening a window into the decision making process with in the deep learning blackbox…
In our last article, we were getting some really good results with CNN when we used a custom text corpus. But will CNN manage to hold onto its lead when it competes with SVM in the battle of sentiment analysis, let’s find that out…
Earlier with the bag of words approach we were getting some really good text classification results. But will that hold, when we take into consideration the sequence of words? There is only one way to find out, let’s get right into the action, where we are doing a head on comparison of traditional approach (Naive Bayes) with a modern neural based one (CNN).
For generic text, word bag approaches are very efficient at text classification. For a binary text classification task studied here, LSTM working with word sequences is on par in quality with SVM using tf-idf vectors. But performance is a different matter…
Sequence respecting approaches have an edge over bag-of-words implementations when the said sequence is material to classification. Long Short Term Memory (LSTM) neural nets with words sequences are evaluated against Naive Bayes with tf-idf vectors on a synthetic text corpus for classification effectiveness.
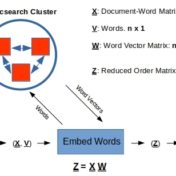
Tf-idf vectors with word-embeddings are analyzed for clustering effectiveness. The text corpus examples considered here indicate that custom word-embeddings can help with clustering
A sister task to classification in machine learning is clustering. While classification requires up-front labeling of training data with class information, clustering is unsupervised. There is a large benefit to unattended grouping of text on disk and we would like to know if word-embeddings can help. In fact, once identified, these… Read more »
In the previous post Word Embeddings and Document Vectors: Part 1. Similarity we laid the groundwork for using bag-of-words based document vectors in conjunction with word embeddings (pre-trained or custom-trained) for computing document similarity, as a precursor to classification. It seemed that document+word vectors were better at picking up on similarities… Read more »