The words that are significant to a class can be used improve the precision-recall trade off in classification. Using the top significant terms as the vocabulary to drive a classifier yields improved results with a much small sized model for predicting MIMIC-III CCU readmissions from discharge notes
Querying with high frequency terms improves recall and, the rare terms precision. The significant terms balance both while offering some discriminative capacity among the latent classes the retrieved documents may belong to. The MIMIC-III dataset is studied here in the context of predicting patient readmission from the discharge notes with Elasticsearch driving the significance measures…
BERT yields the best F1 scores on three different repositories representing binary, multi-class, and multi-label/class situations. BoW with tf-idf weighted one-hot word vectors using SVM for classification is not a bad alternative to going full bore with BERT however, as it is cheap.
Attention is like tf-idf for deep learning. Both attention and tf-idf boost the importance of some words over others. But while tf-idf weight vectors are static for a set of documents, the attention weight vectors will adapt depending on the particular classification objective. Attention derives larger weights for those words that are influencing the classification objective, thus opening a window into the decision making process with in the deep learning blackbox…
Feature space cracking new data introduces potentially useful new classes if detected. Spurts in the rate of increase of new data points with a less than acceptable classification confidence, indicate that new data zones are being carved out in the feature space…
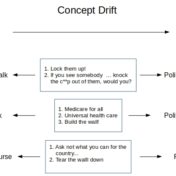
Concept drift is a drift of labels with time for the essentially the same data. It leads to the divergence of decision boundary for new data from that of a model built from earlier data/labels. Scoring randomly sampled new data can detect the drift allowing us to trigger the expensive re-label/re-train tasks on an as needed basis…
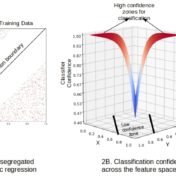
Logistic Regression has traditionally been used as a linear classifier, i.e. when the classes can be separated in the feature space by linear boundaries. That can be remedied however if we happen to have a better idea as to the shape of the decision boundary…
SVM with Tf-idf vectors edges out LSTM in quality and performance for classifying the 20-newsgroups text corpus.
Earlier with the bag of words approach we were getting some really good text classification results. But will that hold, when we take into consideration the sequence of words? There is only one way to find out, let’s get right into the action, where we are doing a head on comparison of traditional approach (Naive Bayes) with a modern neural based one (CNN).
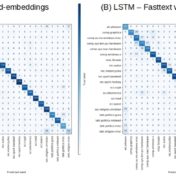
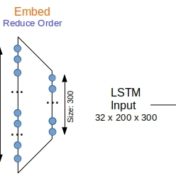
For generic text, word bag approaches are very efficient at text classification. For a binary text classification task studied here, LSTM working with word sequences is on par in quality with SVM using tf-idf vectors. But performance is a different matter…